
1. SaaSにおけるスケーラビリティ設計の重要性
SaaSではユーザー数やデータ量が増加し続けるため、リソースを柔軟に拡張・縮小できる「スケーラビリティ」が不可欠です。対応できなければ遅延や停止を招き、顧客離れにつながります。クラウド基盤を活用すれば、需要変動に応じたリソース調整が可能となり、競争優位を確保できます。
2. 負荷対策の基本要素
主な要素は以下の通りです。
・ロードバランシング:トラフィックを複数サーバーに分散
・スケーリング:垂直(CPU/メモリ増強)・水平(サーバー増設)
・キャッシュ/CDN:アクセス集中を緩和
・マイクロサービス化:機能単位で独立スケール
・DB分散設計:リードレプリカやシャーディングで負荷分散
これらを組み合わせることで、ピーク時にも安定稼働する基盤を構築できます。
3. 自動スケーリングのしくみとベストプラクティス
自動スケーリングは、CPU・メモリ・レイテンシなどを基にリソースを動的に調整する仕組みです。ベストプラクティスは以下の通り、
・適切なメトリクス選定
・閾値とクールダウン時間の最適化
・スケールアウト/インの両対応
・冗長構成による停止防止
・コスト最適化を考慮した設計
4. マルチテナント構成とスケーラビリティの関係
マルチテナント構成はコスト効率が高い一方、負荷の影響が全体に波及しやすいという課題があります。重要なのは「テナントごとの負荷・データ分離」「リソース共有設計」「増加時の自動拡張対応」です。
5. モニタリング・可観測性・運用の視点
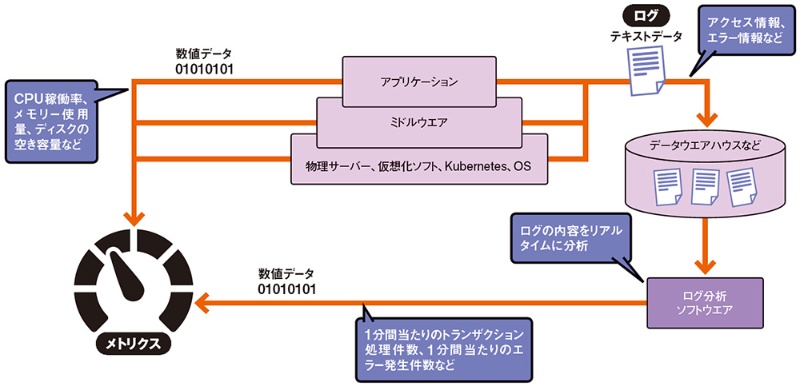
スケーラビリティ設計・自動スケーリングを効果的に運用するためには、モニタリングと可観測性(observability)が欠かせません。
・ログ、メトリクス、トレースを統合してリアルタイムで状況を把握。
・ボトルネックや異常な負荷増大を早期検知できるアラート設計。
・SLAやパフォーマンス要件の達成状況を定期的にレビュー。
・運用チームがスケーリング設計やロード分散設計を理解し、変更時に適切に対応できる体制を持つ。
これらがないと、せっかくスケーラブルな設計をしていても、実際の運用で性能が劣化してしまうことがあります。
6. よくある落とし穴と対策
スケーラビリティ設計/自動スケーリングでよく見られる失敗例とその対策を挙げます。
・過剰スケーリングによるコスト肥大:負荷ピークを過大見積もってリソースを過剰に用意してしまう。 → 適切な負荷予測とスケールイン設計が大切。
・スケーリング待ちのボトルネック発生:メトリクス閾値が遅れて反応し、ユーザー体験が悪化。 → メトリクスポーリング間隔の短縮/予測型スケーリングを検討。
・マルチテナント設計でのテナント間影響:あるテナントの負荷が他テナントを巻き込んで全体性能低下。 → テナントごとのリソース制限・隔離を設計に入れる。
・モニタリングが甘くて異常が発見できない:運用時に負荷増加を見逃し、拡張が手動で遅れる。 → オブザーバビリティ設計を最初から組み込む。
・データベース負荷の見落とし:アプリケーション層はスケールできても、DBがボトルネックとして残る。 → DBスケーリング・キャッシュ・レプリケーションを設計に含める。
SaaS事業において「スケーラビリティ設計=負荷対策+自動スケーリング」の構成は、単なる技術選定以上に、運用・設計・モニタリングを一体化させることで初めて効果を発揮します。クラウドネイティブな基盤、マルチテナント設計、モニタリングの体制、さらにコスト管理という観点まで含めて設計を進めることで、利用者拡大時にもサービス品質を維持しながら、運用コストを最適化できます。ぜひ、この記事を通じて自社SaaSのスケーラビリティ設計を改めて見直すきっかけにしていただければ幸いです。





