
1. デプロイ&インフラ構築とは何か
デプロイとは、開発したアプリケーションを実際の利用環境へ反映する作業です。しかし実務では、単なるアップロードではなく、「安全に変更を届ける仕組み全体」を意味します。
インフラ構築も同様で、サーバーを用意するだけではありません。以下を含めた総合的な設計が必要になります。
・ネットワーク構成
・データベース運用
・セキュリティ
・ログ収集
・スケーリング
・障害復旧
・デプロイパイプライン
つまり本番環境とは、「動く環境」ではなく「運用できる環境」を指します。
2. 本番環境で押さえるべき基本要素
環境分離
開発環境・ステージング環境・本番環境を分離することで、検証不足のコードが本番へ入るリスクを減らします。
典型構成:Local → Development → Staging → Production
特に重要なのは、「本番だけ設定が違う」状態を避けることです。
そのために使われるのが IaC(Infrastructure as Code)です。
代表例:

IaCを導入すると、
・環境再現性
・差分管理
・レビュー可能性
・が大きく向上します。
安全なデプロイ戦略
本番では「失敗する前提」で設計する必要があります。
Blue/Green Deployment
・Blue = 現在稼働中
・Green = 新バージョン
切り替え後に問題があれば即座に戻せます。
メリット:
- ロールバックが高速
- ダウンタイムが少ない
デメリット:
- インフラコスト増加
Canary Release
一部ユーザーだけ新バージョンへ流します。
5% → 20% → 50% → 100%
特に大規模サービスで有効です。
適しているケース:
・トラフィックが大きい
・障害影響を限定したい
・ABテストしたい
Feature Flags
機能をデプロイではなく「ON/OFF」で制御します。
利点:
・リリースと公開を分離できる
・即時停止可能
・段階公開できる
近年のモダン開発ではかなり重要な考え方です。
3. CI/CDによる自動化
CI/CDは、変更を継続的に安全投入するための基盤です。
CI(Continuous Integration)
コード統合時に自動で検証します。
典型例:

これにより、
・壊れたコード
・型エラー
・テスト失敗
を早期発見できます。
CD(Continuous Delivery / Deployment)
CI通過後にデプロイまで自動化します。
代表ツール:

実務で重要な考え方
CI/CDで最も重要なのは「再現性」です。
つまり、
・誰が実行しても
・同じ手順で
・同じ結果になる
・状態を作ることです。
属人的なデプロイは、長期運用でほぼ必ず事故になります。
4. コンテナとクラウドネイティブ設計
Dockerによる環境統一
Dockerは「動作環境そのもの」をコンテナ化します。
Code + Runtime + Dependencies をまとめて管理できるため、
・ローカルでは動く問題
・環境差異
・ライブラリ不整合
を減らせます。
特にNode.js系では非常に効果があります。
Kubernetesの役割
Kubernetes(K8s)はコンテナ管理基盤です。
できること:
・自動スケーリング
・自動復旧
・ロードバランシング
・ローリングアップデート
ただし、小規模開発では運用コストが重くなる場合があります。
そのため最近は、
・ECS
・Cloud Run
・App Runner
・Railway
・Render
など、マネージド基盤を選ぶケースも増えています。
Cloud-native の考え方
クラウドネイティブでは、
・水平スケール
・自動復旧
・Immutable Infrastructure
を前提に設計します。
つまり、「サーバーを直す」のではなく、「壊れたら作り直す」思想です。
5. Monitoring(観測性)の設計
本番環境では、「障害をゼロにする」ことは困難です。
重要なのは、
・早く検知
・原因特定
・素早く復旧
できることです。
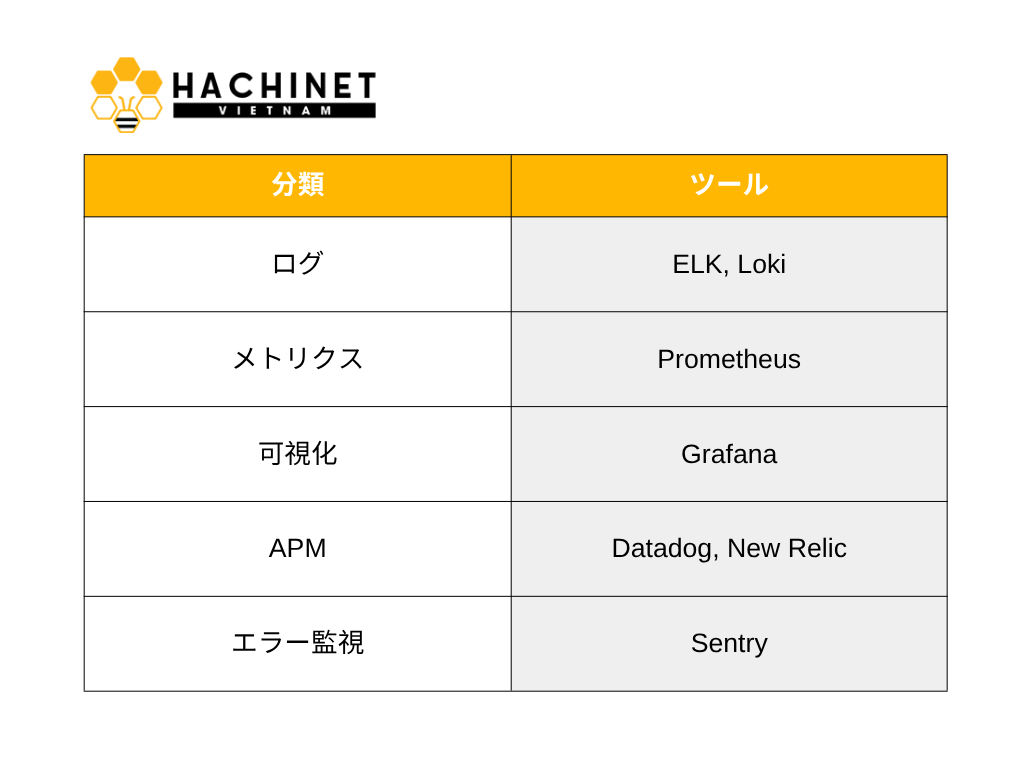
Observabilityの3本柱
Logs
イベント記録。
例:

Metrics
数値監視。
例:
・CPU
・Memory
・Error Rate
・Response Time
Traces
リクエスト追跡。
マイクロサービス時代では特に重要です。
代表ツール
SLO/SLAの重要性
「どの程度止まってよいか」を定義します。
例:99.9% availability
SLOを決めることで、
・過剰品質
・不十分品質
を避けられます。
6. セキュリティ設計
シークレット管理
以下をGitへ直接置いてはいけません。
・API Key
・DB Password
・JWT Secret
代表的な管理方法:

最小権限の原則
IAMでは、必要最小限のみ許可を徹底します。
管理者権限の乱用は重大事故につながります。
脆弱性スキャン
CIへ組み込みます。
例:
・npm audit
・Trivy
・Snyk
・Dependabot
依存ライブラリ経由の脆弱性は非常に多いため、継続監視が必要です。
7. データベース運用と復旧設計
バックアップ戦略
バックアップは「取得」より「復元できるか」が重要です。
最低限必要なのは:
・定期バックアップ
・復元テスト
・世代管理
です。
Expand / Contract Migration
DB変更を段階的に行います。
・危険な例:カラム削除 → 即本番
・安全な流れ:追加 → 並行運用 → 移行 → 削除
大規模システムでは必須の考え方です。
8. 実務でよくある失敗
「本番だけ違う」
典型例:
・ENV差異
・Node version差異
・DB設定差異
IaCとDockerでかなり防げます。
監視不足
障害後に、何が起きたか分からない
状態は非常に危険です。
最低限必要なのは:
・エラーログ
・リクエストログ
・アラート通知
です。
手動デプロイ依存
人間依存は再現性を壊します。
特に危険なのは:
・SSH直接操作
・手順書だけ運用
・本番手動編集
です。
9. 小規模〜大規模までの実践構成例
MVP・小規模

特徴:
・最速構築
・運用負荷小
・少人数向け
中規模SaaS

大規模サービス

ここでは「開発速度」より「運用安定性」が優先されます。
デプロイとインフラ構築の本質は、「コードを置くこと」ではなく、「安全に変更を継続できる運用基盤を作ること」にあります。現代の本番環境では、CI/CD、自動テスト、IaC、観測性、セキュリティ、復旧設計までを一体として考える必要があります。特に重要なのは、障害を完全になくすことではなく、障害を素早く検知し、安全に戻せる設計を最初から組み込むことです。クラウドや自動化技術が進化した現在だからこそ、「壊れない」より「壊れても運用できる」システム設計が、実務で最も価値を持つようになっています。





